
The "200 OK" Lie
Traditional software is deterministic. LLMs are probabilistic. This single sentence reframes everything you thought you knew about production reliability.
In traditional APIs, an HTTP 200 response is a handshake of truth-the system did what you asked. In the world of Large Language Models, that same 200 status code can wrap a hallucinated answer, a dangerously incorrect medical recommendation, or a $45,000 token bill disguised as a successful response. The status code is technically accurate and operationally meaningless at the same time.
As we move deeper into the Agentic Era-where AI systems perform multi-step reasoning, call external tools, and make autonomous decisions-this gap between “the API returned 200” and “the AI did the right thing” grows into a chasm.
Thesis : LLM observability is not a debugging tool bolted on after launch. It is the control plane for safety, cost governance, and reliability in any production AI system-non-negotiable from day one.

Critical Challenges of Operating LLMs in Production
The 4 Critical Production Challenges
- Silent Failures & Hallucinations:Undetected errors that reach users.
- Runaway Costs:$0 → $45K surprise bills from token bloat.
- Debugging Nightmare:4 hours/bug without tools → 15 minutes/bug with observability.
- Production Drift:Works locally, fails in production-40% failure rate.
1. Silent Failures & Hallucinations
Your healthcare chatbot calls the Claude API. Status: 200 OK. Your logs say success. But the response recommends a contraindicated drug for a patient with kidney disease. The patient is hospitalized. Your monitoring infrastructure never flagged a single error-because there was none to flag.
This is the hallucination problem at its most severe. LLMs generate tokens probabilistically, defaulting to confident-sounding guesses when uncertain. They have no built-in “I don’t know” mode. HTTP 200 confirms a response was delivered; it says nothing about whether that response is true.
- Without tools:Manual review of thousands of outputs is infeasible-errors surface only after patient harm.
- With tools:Every LLM call is logged (input, output, model, tokens). Outputs are scored for accuracy and flagged automatically for human review.
2. Runaway Costs – The $45,000 Surprise
- Month 1 LLM costs:$500
- Month 2:$8,000
- Month 3:$45,000
By the time finance notices, you have spent $50,000 on a feature generating $2,000 in revenue. Without observability, you cannot identify which prompt, user, or workflow is responsible.
Common hidden causes:
- Passing a full 100k-token document instead of a 5k-token summary-a 20× cost multiplier.
- Long conversation context replayed with every turn-exponential token growth.
- Defaulting to GPT-4 for tasks GPT-3.5 handles adequately.
- Retry loops on transient failures-one request becomes ten API calls.
- No prompt caching-identical prompts re-executed thousands of times.
With observability, a dashboard surfaces cost by model, prompt, and time period. A spike is visible immediately: “GPT-4 accounts for 80% of costs-find the expensive prompt at $10 per request.” Replacing a 100k-token input with a 5k summary cuts that function’s cost by 95%.
3. The Debugging Nightmare
A user reports an error. Your logs show [ERROR] LLM timeout. That’s all. Which exact prompt failed? Unknown. What context was sent? Unknown. How many tokens? Unknown. One affected user or ten thousand? Unknown.
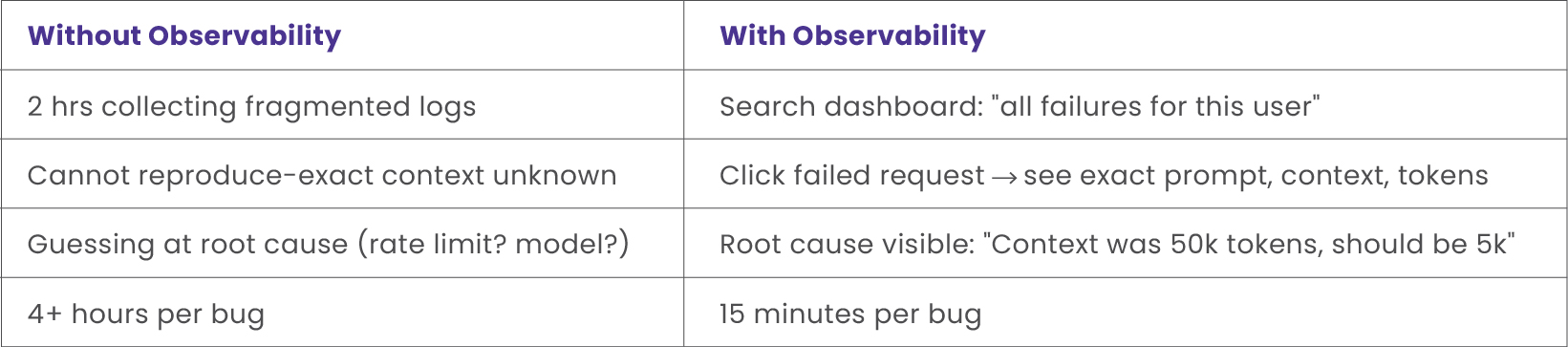
For a team of five engineers, eliminating 4-hour debug cycles saves 40 hours per week-two hours per person redirected to building features.
4. Production Drift – “Works Locally, Fails in Prod”
Your prompt is perfect in local testing. In production, it fails 40% of the time. Without observability, this is invisible until users complain.
- Context history drift:Local test has 1 message; production conversation has 50.
- Temperature drift:Local uses 0 (deterministic); production defaults to 1.0.
- Model drift:Local uses GPT-4; production silently routes to GPT-3.5.
- Input drift:Local queries are English; production users write in Spanish, Arabic, Chinese.
- Context window drift:Production inputs exceed context limits, causing silent truncation.
Observability places local test results and production failures side-by-side. The difference becomes instantly visible: “History is 47 messages in prod vs 1 locally-that’s why it’s failing.” Fix deployed in ten minutes.
The Solution in Practice - Curie Case Study
In Curie, we utilize observability and monitoring frameworks to gain a deep understanding of our token usage. By analyzing this telemetry, the team actively works to reduce operational costs by minimizing unnecessary token consumption while ensuring the accuracy and quality of the LLM output is strictly maintained.
Additionally, we use these frameworks to continuously monitor application latencies, allowing us to pinpoint bottlenecks and proactively improve response times. Finally, the historical data captured by our observability stack is vital for deriving accurate monthly cost forecasts and tracking our budget over time.
Key Outcomes from Project Curie:
- Reduced unnecessary token consumption through targeted prompt optimization
- Identified and resolved latency bottlenecks in multi-step agent workflows
- Enabled monthly cost forecasting using historical data
- Maintained output quality while achieving significant cost savings
The Arsenal - Langfuse vs LangSmith
While several LLM observability tools exist in the market, two have emerged as category leaders for production use: Langfuse and LangSmith. Here is the technical breakdown based on verified specifications.
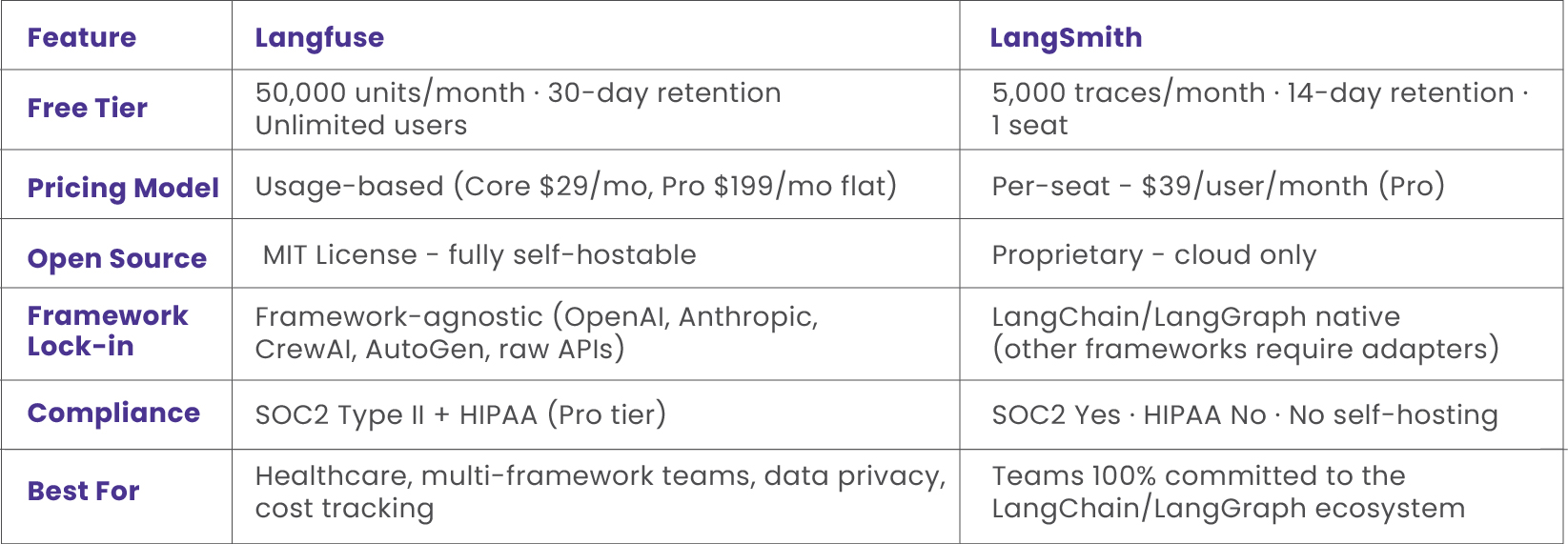
Choose Langfuse if:
- You need SOC2 or HIPAA compliance for a healthcare or regulated environment.
- Data privacy requires self-hosting - Langfuse ships under MIT license.
- Your stack uses multiple frameworks (CrewAI, AutoGen, raw OpenAI, Anthropic).
- Team size is growing-no per-seat pricing means costs scale predictably.
Choose LangSmith if:
- Your entire stack is LangChain or LangGraph - one environment variable enables full tracing.
- You want the most seamless agent graph debugging UI available today.
- Team headcount is fixed and small (per-seat pricing remains manageable).
How to Implement Observability - Getting Started
Both tools offer a path from zero to production tracing in under an hour. Here are working code examples drawn directly from official documentation.
Langfuse – 5-Minute Integration
Install the SDK, initialize with your API keys, wrap your OpenAI call in a trace, and log the generation.
Every parameter-input, output, model, token usage-becomes queryable in the Langfuse dashboard.
from openai import OpenAI
langfuse = Langfuse(api_key="pk_...")
client = OpenAI()
# Create a trace for this workflow
trace = langfuse.trace(name="medical-diagnosis")
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Patient fever 102F"}]
)
# Log every detail - input, output, model, tokens
trace.generation(
name="gpt-4-call",
input={"symptoms": "fever 102F"},
output=response.choices[0].message.content,
model="gpt-4",
usage={"input": 10, "output": 50}
)
# → View traces at https://cloud.langfuse.com
LangSmith – 1-Line Setup (LangChain Only)
If your application is built on LangChain, LangSmith requires only environment variables. Every LangChain
invocation is automatically traced-no code changes to your business logic.
from langsmith import traceable
@traceable(name="my-chain")
def my_langchain_function(input_data):
# Your existing LangChain code here
result = chain.invoke(input_data)
return
# → Automatically traced at https://smith.langchain.com
Conclusion - Bringing Visibility to the Black Box
As AI systems become more agentic and autonomous-reasoning across multiple steps, calling external tools, and making decisions with real-world consequences-the need for deep visibility into their behavior will only intensify. LLM observability is no longer a “nice to have” debugging utility. It is the foundational layer for building AI applications that are reliable, safe, and scalable. The question is not whether to implement it-it is how quickly you can start.
Insights That Drive Impact
Healthcare is evolving faster than ever — and those who adapt are the ones who will lead the change.
Stay ahead of the curve with our in-depth insights, expert perspectives, and a strategic lens on what’s next for the industry.


