
Abstract
Persistent memory represents a major leap forward in the design of Large Language Models (LLMs), enabling systems to move beyond short-lived conversational context and toward true long-term intelligence. This article presents an engineering framework for implementing persistent memory in LLM-based applications through a multi-tier context system. The architecture integrates short-term session caching, mid-term vector memory, and long-term structured persistence to emulate cognitive memory layers. By combining these tiers with optimized retrieval, scoring, and decay policies, developers can create systems that maintain continuity, relevance, and personalization across sessions. The article also provides practical examples and code-level guidance on orchestrating retrieval pipelines using vector stores and NoSQL databases such as Fire store.

Introduction
LLMs such as GPT, Claude, and Gemini have transformed natural language understanding and generation, but they remain limited by the finite context window. Once this window overflows, older information is forgotten, preventing long-term consistency and personalization.
Human cognition, however, thrives on accumulated memory balancing immediate awareness, short-term retention, and long-term knowledge. Replicating this in AI requires a persistent memory architecture capable of storing, retrieving, and refining information beyond session boundaries.
This article explores how such persistence can be engineered through a multi-tier memory design, enabling LLMs to act not just as responders but as adaptive, contextually aware systems. The approach blends insights from cognitive architectures with practical implementations using caches, vector databases, and NoSQL backends.
The Multi-Tier Memory Architecture
Persistent memory for LLMs can be viewed as a hybrid hierarchy that is short-term, mid-term, and long-term layers each optimized for speed, relevance, and durability. Together, they mirror how humans process experience, immediate context, recent history, and durable knowledge
Short-Term Context: The Session Cache
Short-term memory corresponds to the model’s working context, the transient buffer that captures the immediate conversation.
a) Storage: Typically maintained in Redis, in-memory arrays, or an application session store.
b) Function: Supports immediate turn-by-turn continuity within a chat session.
c) Lifecycle: Automatically cleared when a session ends or times out.
For example, a chatbot remembers a user’s last three queries (“Show my transactions”, “Sort by date”, “Filter credit only”) to maintain conversational coherence.
Mid-Term Context: The Vector Store
The vector memory tier serves as the semantic bridge between transient interactions and long-term understanding. It stores embeddings of high-dimensional vector representations of text enabling the system to recall semantically related information even when phrased differently.
Implementation Options: FAISS, Pinecone, Weaviate, or Chroma DB.
Functionality:
a) Semantic search based on embedding similarity.
b) Relevance scoring using cosine similarity.
c) Periodic pruning through decay or recency weights.
For example, A user discussing “investment portfolio rebalancing” in March and “asset mix optimization” in July would trigger the same underlying vector cluster, ensuring conceptual continuity
Long-Term Context: The NoSQL Memory Store
Long-term memory persists structured data across sessions. This layer acts as the model’s factual and historical knowledge base, storing user profiles, decisions, and derived summaries.
Implementation Options: Google Firestore, MongoDB, DynamoDB.
Design Considerations:
a) Apply data retention and anonymization policies for compliance.
b) Store summaries instead of full transcripts to reduce retrieval overhead.
c) Use metadata fields such as topic, user_id, relevance_score, and last_accessed for efficient indexing.

Relevance Scoring and Decay Policies
Not all memories deserve equal attention. Over time, some must fade while others are reinforced – a principle known as selective retention.
Relevance Scoring
Each stored memory item whether from a vector database or a structured NoSQL record is ranked through a weighted relevance system that balances multiple factors. Semantic similarity measures how closely the query aligns with stored content, often using cosine similarity between embeddings. Recency weight ensures that newer interactions are prioritized, reflecting their current relevance. Interaction frequency gives additional importance to topics or entities that the user frequently references, reinforcing continuity across sessions. Lastly, explicit feedback, such as user confirmations or corrections, dynamically strengthens or weakens memory entries. Combined, these factors enable the LLM to retrieve context that is both meaningful and temporally relevant, supporting adaptive and personalized responses.
Mathematically, a hybrid relevance score can be defined as:
Score = α (Similarity) + β (Recency) + γ (Frequency)
where α, β, and γ represent tunable parameters controlling the influence of each factor in the ranking process.
Decay Mechanisms
To avoid memory bloat, decay policies gradually reduce the weight or retention of old data. The memory system applies decay mechanisms to keep stored information relevant and efficient. In time-based decay, memory scores gradually decrease after a set period, phasing out outdated data. Event-driven forgetting removes old entries when newer, more relevant ones appear, while importance-based persistence retains high-value or frequently used information. Together, these methods ensure the system balances freshness with long-term relevance.
For example, an AI assistant may retain “project deadlines” longer than casual greetings, based on interaction context tags.
Retrieval Orchestration: How Multi-Tier Memory Works Together
Retrieval orchestration defines how information flows between tiers. It’s the decision engine that determines where to look, what to retrieve, and how to merge results.
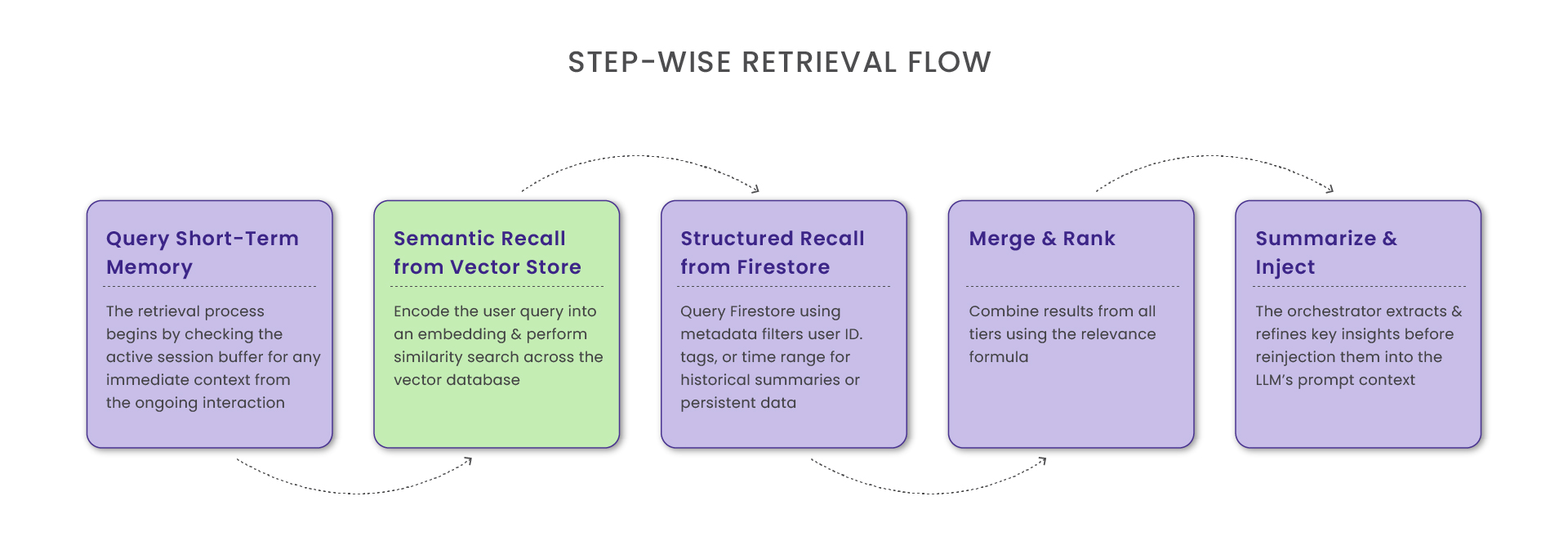
Step-wise Retrieval Flow
a) Query Short-Term Memory: The retrieval process begins by checking the active session buffer for any immediate context from the ongoing interaction. If relevant information is found within this short-term cache, the system reuses it directly to maintain continuity and minimize latency. However, if no suitable context exists in the session memory, the process seamlessly escalates to a vector search, querying the mid-term semantic memory to retrieve related information based on similarity.
b) Semantic Recall from Vector Store : Encode the user query into an embedding and perform a similarity search across the vector database.
c) Structured Recall from Firestore: Query Firestore using metadata filters user ID, tags, or time range for historical summaries or persistent data.
d) Merge and Rank: Combine results from all tiers using the relevance formula.
e) Summarize and Inject: The orchestrator extracts and refines key insights before reinjecting them into the LLM’s prompt context.
Example: Retrieval Pipeline in Code
This pipeline exemplifies hybrid retrieval fast semantic recall from vectors paired with durable factual grounding from structured stores.
Example: Retrieval Pipeline in Code
This pipeline exemplifies hybrid retrieval fast semantic recall from vectors paired with durable factual grounding from structured stores.
# -----------------------------
# Step 1: Vector Retrieval
# -----------------------------
# Convert user query into an embedding and search vector memory
query_embedding = embedder.encode(user_query)
vector_hits = vector_store.search(
query_embedding,
top_k=5
)
# -----------------------------
# Step 2: Structured Memory Retrieval
# -----------------------------
# Fetch user-specific notes, preferences, tasks, or metadata
structured_hits = firestore.query(
collection="user_memory",
filters={
"user_id": user_id,
"tags": query_tags
}
)
# -----------------------------
# Step 3: Merge, Rank, and Summarize
# -----------------------------
# Combine unstructured (vector) and structured memory hits
combined = vector_hits + structured_hits
# Rank results by semantic relevance to the user query
ranked = rank_by_relevance(combined)
# Compress ranked memory into a short, optimized context window
context_summary = summarize_context(ranked)
# Prepare final prompt for the LLM with memory included
final_prompt = f"""
{context_summary}
User: {user_query}
"""
# -----------------------------
# Step 4: Generate Response
# -----------------------------
response = llm.generate(final_prompt)
print(response)Operational Strategies and Optimization
Designing persistent memory is not just about retrieval; it’s about sustainability, security, and scalability.
Performance Optimization
To optimize performance, the system uses several strategies. Batch embedding generates embeddings asynchronously to reduce latency, while sharding partitions vector and NoSQL stores by domain or user for faster access. Caching stores high-frequency queries in Redis to enable near-instant retrieval, and incremental summarization periodically condenses historical data into concise thematic summaries, maintaining efficiency without losing essential context.
Privacy and Security
To ensure security and privacy, the system encrypts sensitive data both in transit and at rest, preventing unauthorized access. It also enforces strict access policies that control who or what can query specific memory layers. Additionally, user consent mechanisms are applied to manage data persistence transparently and maintain compliance with privacy standards.
Cost and Scalability
The system manages costs through tiered storage using RAM for cache, SSD for vector databases, and cloud storage for Firestore. It applies TTL policies for automatic cache eviction and indexes Firestore reads by relevance and date to improve query efficiency.
Future Directions
As LLMs advance toward lifelong learning, persistent memory will become a core component of their architecture. Emerging innovations such as episodic vector memory which clusters related interactions into holistic “episodes” contextual understanding and recall. Dynamic memory allocation further optimizes system performance by adjusting memory usage based on interaction complexity, ensuring efficient resource utilization. Meanwhile, privacy-preserving federated memory allows models to synchronize learned context across systems without exposing raw data, maintaining both personalization and data security. Together, these developments pave the way for autonomous contextual intelligence, where models continuously learn, remember, and adapt over time, much like human cognition.
Conclusion
Persistent memory transforms LLMs from reactive systems into contextually aware collaborators. The proposed multi-tier architecture comprising a fast session cache, an intelligent vector layer, and a durable NoSQL backend mirrors human cognitive layering.
By orchestrating relevance scoring, decay, and hybrid retrieval, developers can build AI systems that preserve context, personalize experiences, and reason coherently across time. Beyond immediate performance gains, this architecture lays the foundation for a truly adaptive AI one that not only learns but remembers.
As organizations deploy LLMs in real-world workflows, persistent memory will define the next frontier of intelligent interaction where knowledge endures, insights evolve, and every conversation adds to a system’s growing understanding of its users.
Curie’s AI system uses a multi-layer memory setup to become smarter over time and give more personalized, consistent responses.
Short-term memory (Session-level cache)
This is like Curie’s immediate memory. It remembers what happened in the current conversation so it can respond quickly and stay consistent.
Mid-term memory (Vector index – Pinecone)
This works like Curie’s “semantic memory.” It stores important information as embeddings, so the system can search and recall relevant knowledge even after the conversation is over.
Long-term memory (Firestore)
This is Curie’s deep storage. It keeps long-lasting things like user preferences, summaries, logs, and historical decisions so Curie can improve across days, weeks, and months.
By combining all three memory types and using smart rules like scoring what’s relevant, deciding what to forget, and mixing different retrieval methods gives us Curie outcomes.
Insights That Drive Impact
Healthcare is evolving faster than ever — and those who adapt are the ones who will lead the change.
Stay ahead of the curve with our in-depth insights, expert perspectives, and a strategic lens on what’s next for the industry.


