
The Hidden Problem Noone Notices in Data
Real-World Evidence (RWE) runs on a constant stream of healthcare data. Hospitals send diagnosis records, treatment details, and patient information through Electronic Health Record (EHR) feeds every day. Most teams watch closely to make sure data arrives on time. But one of the biggest risks doesn’t come from missing data – it comes from data that looks fine but quietly changes.
Imagine this: a hospital updates its coding system from ICD-9 to ICD-10 overnight. Files still arrive. Dashboards still refresh. Nothing breaks. But suddenly, diagnosis trends shift. Patient cohorts look smaller. Long-standing analytics don’t match historical patterns. This is what many organizations call a silent failure – when the pipeline works, but the meaning of the data changes underneath.
What is Coding Format Change & Why Does It Matter?
In hospitals, every diagnosis, procedure, and medical event gets assigned a code. For years, hospitals in the US used a coding system called ICD-9. Then, in 2015, most switched to ICD-10 – a newer, more detailed system. The two systems look very different. A Type 2 Diabetes diagnosis in ICD-9 was coded as 250.00. In ICD-10, that same diagnosis becomes E11.9.
“Same patient. Same disease. Completely different code. And if your data system does not know a switch happened, it treats them as two different things.”
For a data pipeline feeding a research study, this transition – even if it happens at just one hospital – can cause serious problems. Patient records may get mislabelled or lost. Disease populations shrink unexpectedly. Treatment comparisons become unreliable. And because no error was ever thrown, no one knows to investigate.
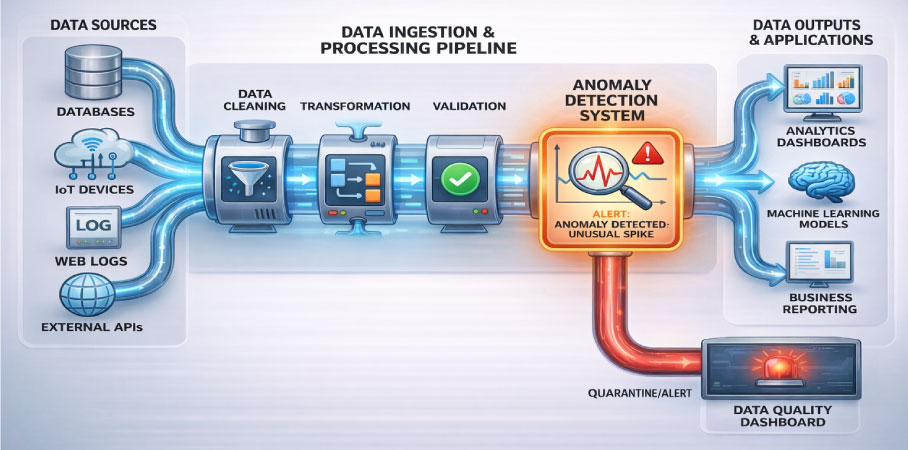
Anomaly Detection as Early Warning System
Anomaly detection is a method of teaching a system to recognize what normal looks like – and then raise a flag whenever something drifts away from that normal. Applied to EHR data pipelines, it works a bit like a hospital vitals monitor. A patient’s heart rate, blood pressure, and temperature are tracked continuously. The moment something goes outside the expected range, an alarm sounds – long before a crisis develops.
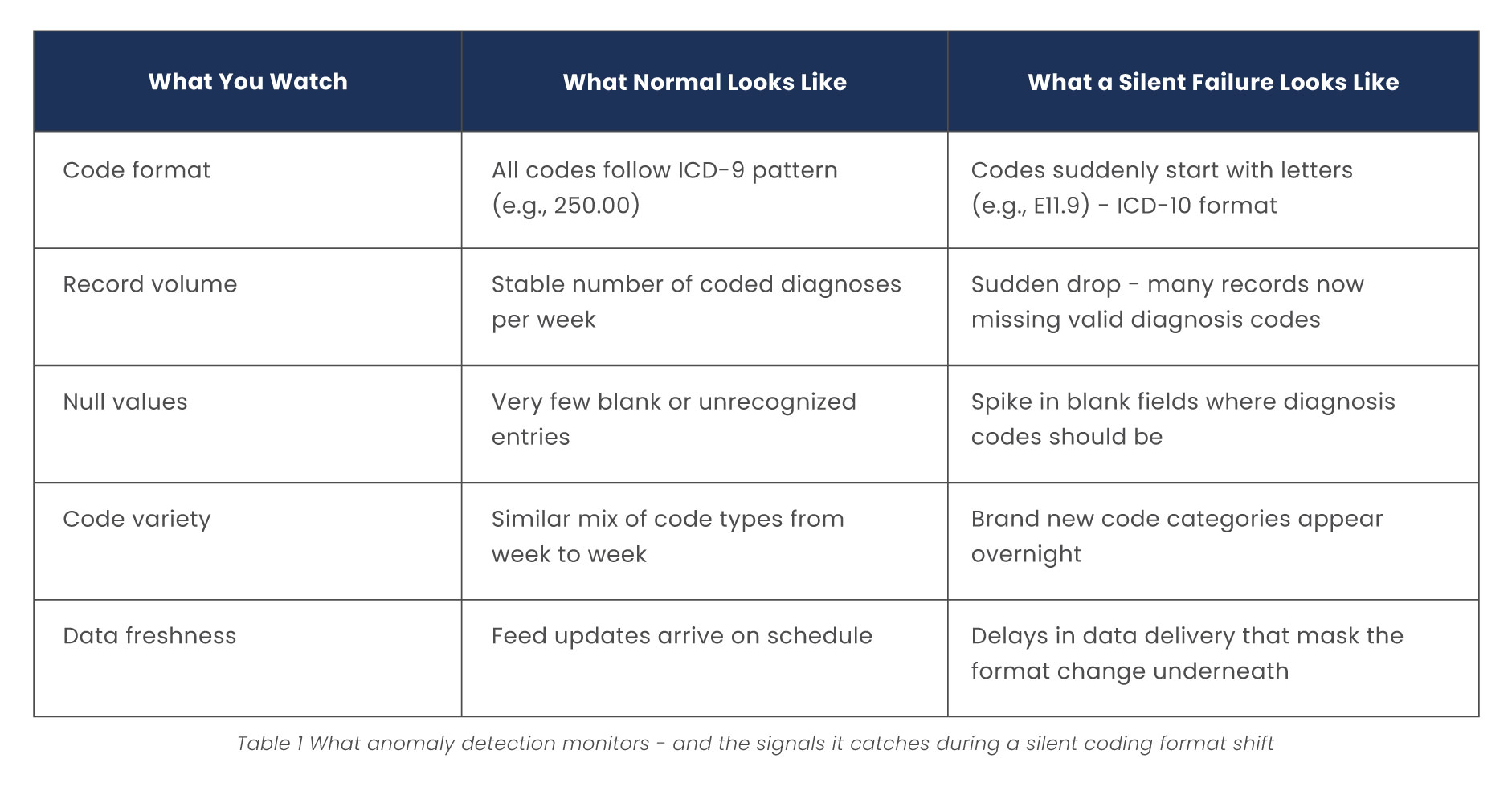
For a data feed from a specific hospital, normal might mean: the diagnosis codes always start with numbers (ICD-9 style), about 300 coded diagnoses arrive per week, and fewer than 2% of code entries are blank or unrecognized. When a hospital switches to ICD-10, several of these patterns break at once and anomaly detection catches that shift immediately.
Here is what that looks like in practice:
Data Observability Watches the Pipeline
Anomaly detection is most powerful when it is part of a broader approach called data observability. The practice of continuously monitoring the health of your data across every stage of its journey, from hospital feed to final analysis dataset.
In an EHR data pipeline, good observability covers five things:
- Freshness - Is the data arriving on time? A delay can be the first sign something changed upstream.
- Volume - Are we receiving roughly the same number of records as usual? A sudden drop often signals a problem.
- Distribution - Are the types and ranges of values consistent? A spike in unfamiliar code patterns is a red flag.
- Schema - Are all the expected fields present with the right data types? A new field appearing (or an old one disappearing) tells a story.
- Lineage - Can we trace where every value came from? If a code change upstream creates blank values downstream, lineage tracking shows exactly where the break happened.

Why Catching it Early Makes all the Difference
The real value of silent failure detection isn’t just knowing something went wrong, it’s knowing fast enough to fix it before it damages your research.
When anomaly detection flags a coding shift early, data teams can quarantine affected records, confirm the transition date with the hospital, apply the right code mapping, and tag the records so analysts know to handle them with care. Clean, trustworthy data gets restored quickly – often before any study is impacted.
In RWE research, that timing gap is everything. A data quality issue caught in week one is a minor inconvenience. The same issue caught six months later can invalidate an entire study. This matters because RWE research isn’t just pulling from one hospital – it spans dozens of sites, each running their own EHR systems on their own update schedules. Coding guidelines change annually. New disease categories get added. Any one of these shifts, left undetected, can quietly skew patient counts, distort treatment comparisons, and undermine the very conclusions your research was built to deliver.
“Building silent failure detection into your data pipeline isn’t an added complexity, it’s the difference between research you can defend and research that only looks reliable.”
Final Conclusion
Real-world evidence depends on data that tells a clear and consistent story. Silent failures make that story harder to trust because nothing looks broken on the surface. By introducing data observability and anomaly detection into EHR pipelines, RWE teams gain a clearer view of how their data evolves. A hospital’s coding update no longer becomes a hidden risk – it becomes an early signal that helps teams adapt quickly and keep insights reliable.
As healthcare data continues to grow in scale and complexity, this kind of proactive monitoring isn’t just helpful – it’s becoming essential for building trustworthy real-world evidence.
Sources
- Garza M, Del Fiol G, Tenenbaum J, et al. (2016). Evaluating common data models for use with a longitudinal community registry. Journal of Biomedical Informatics, 64, 333-341.
- Cai T, Cai F, Myles JD, et al. (2020). Learning from EHR Data: Challenges and Opportunities. Annual Review of Biomedical Data Science, 3, 411-432.
- Klann JG, Estiri H, Weber GM, et al. (2021). Data model harmonization for the All of Us Research Program: Transforming i2b2 data into the OMOP common data model. PLOS ONE, 16(1), e0246199.
Insights That Drive Impact
Healthcare is evolving faster than ever — and those who adapt are the ones who will lead the change.
Stay ahead of the curve with our in-depth insights, expert perspectives, and a strategic lens on what’s next for the industry.


