
Vector-native search now powers many retrieval and reasoning workloads. As teams scale from prototypes to production, three constraints dominate: latency at user-facing percentiles, the ability to scale under concurrency, and the cost of memory, compute, and network. This article presents a practical blueprint for engineers who need to deliver consistent recall within a strict latency budget while keeping spend predictable. It explains how common index families behave, how to shard and replicate, how to lay out embeddings in memory, how to combine metadata filters with vector search, how to benchmark honestly, and how to tune for high concurrency. The goal is an architecture that meets service level objectives with clear dials and measurable trade-offs.
Terminology primer
Embedding. A numeric vector that represents content for similarity search.
Vector dimension. The number of features in each embedding. Higher values increase expressiveness and cost.
Similarity metric. The rule used to compare vectors, such as cosine similarity or inner product.
Recall at k. The share of true neighbours that appear in the top k results.
Latency percentiles. p50, p95, and p99 describe median and tail response times.
Approximate nearest neighbour search. A faster search that targets high recall rather than exact results.
Flat index. An exact scan over all vectors. It is simple and expensive at scale.
HNSW. A graph index with two main controls. M sets neighbour degree and ef search sets query breadth.
IVF. A clustered index with two main controls. nlist sets the number of clusters and nprobe sets how many clusters each query scans.
IVF with Product Quantization. A compressed IVF variant that cuts memory with a small loss in accuracy.
Sharding. Splitting the corpus across machines for scale or isolation.
Replication. Keeping copies to improve availability and reduce tail latency.
Hybrid retrieval. Filter candidates with metadata and then rank with vector search.
Memory tiers. Hot data in memory, warm data in memory-mapped files, cold data in object storage.
SIMD and NUMA. Contiguous arrays enable fast vector math and threads should stay close to their data.
Cache warmup. Preload hot structures so early queries are fast.
Service level objective. A target for recall and latency that the system must meet.
The performance target and the latency budget
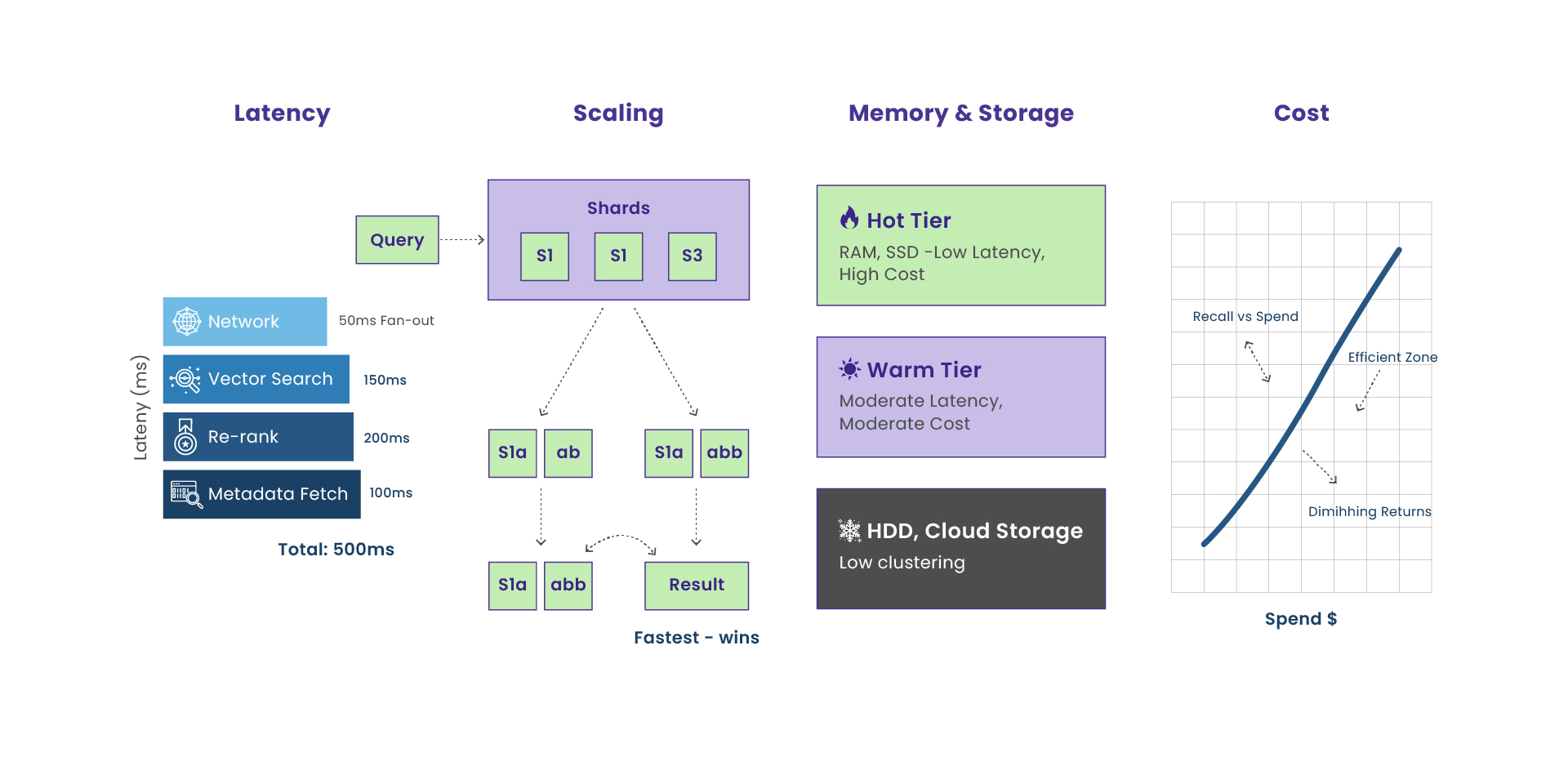
Begin by setting explicit service targets. Teams often aim for an end-to-end latency under one hundred and twenty milliseconds at the ninety-fifth percentile with recall at ten above ninety percent. Break the time into four parts that you can measure: network, vector search, re-ranking, and metadata fetch. A simple histogram or waterfall chart that shows each segment will tell you where to focus. If network time is stable but vector search time dominates at high load, you will tune index parameters and memory layout. If metadata fetch time dominates, you will improve the hybrid retrieval path.
Index internals you actually need to operate
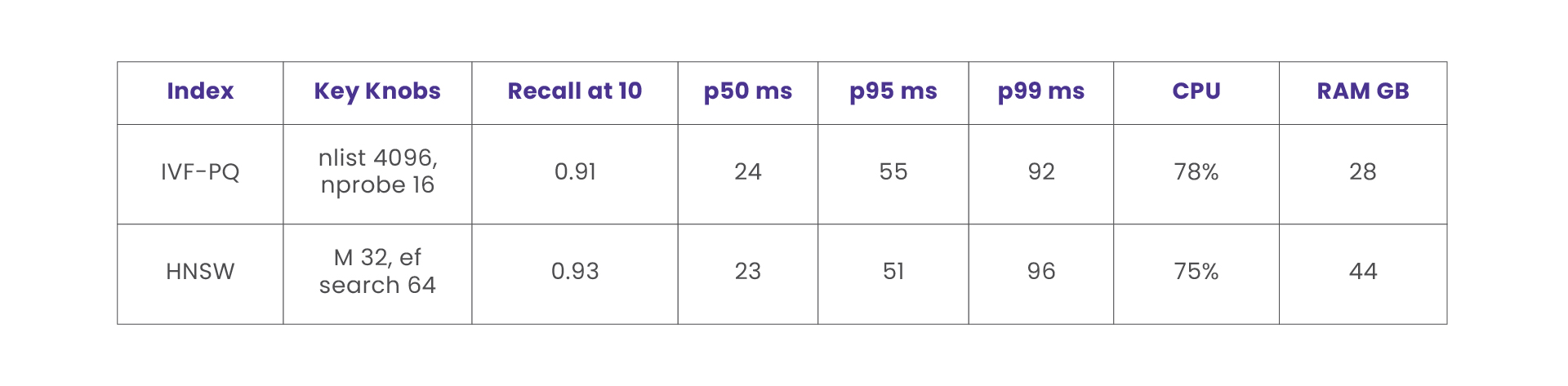
There are three index families most teams rely on. Flat indexes perform exhaustive comparisons and provide exact recall with the highest cost at scale. HNSW, which stands for Hierarchical Navigable Small World graphs, organizes vectors as a layered proximity graph. The important dials are M, which controls the neighbor degree, and ef search, which controls the breadth of the query walk. IVF, which stands for Inverted File Index, clusters the space into nlist coarse cells and probes nprobe of them at query time. IVF with Product Quantization compresses residuals into short codes that reduce memory usage and improve cache locality. The practical trade-off is that higher recall requires more work per query. HNSW and IVF expose that work through ef search and nprobe. The right choice depends on update rates, memory limits, and the number of vectors.

Sharding and replication patterns that keep tail latency in check
Sharding decides how you split the corpus. A multi-tenant system often shards by tenant or by owner to keep isolation and simplify rights checks. A single large corpus benefits from sharding by semantic cluster so that related vectors live together and warm the same lists and graph neighbourhoods. Replication reduces tail latency. A coordinator can fan out a query to multiple replicas and return the fastest valid response while honouring read-after-write rules. Keep shard fan-out limited, and only increase replication when contention or hotspotting is visible in measurements.
Embedding storage and memory layout that serve the hot path
Choose numeric type and compression deliberately. Float32 provides the highest fidelity at a memory cost. Float16 or bfloat16 halves the footprint with a small loss in similarity accuracy. Product Quantization or Optimized Product Quantization compresses vectors into codes that can reduce memory by an order of magnitude. Store vectors contiguously to enable Single Instruction Multiple Data operations. Align arrays to cache line boundaries and consider pinned memory when you offload searches to a graphics processing unit.
Use a three tier model. Keep hot vectors in random access memory. Keep warm vectors in memory-mapped files so the operating system page cache can assist. Keep cold vectors in an object store and hydrate them during planned backfills and rebuilds. On deploy, warm caches by touching HNSW entry points and by preloading the most frequently probed inverted lists.
Hybrid retrieval with Firestore and a vector store

Many applications combine metadata filtering with approximate nearest neighbour search. A common pattern filters candidates in Firestore and then refines the results in FAISS or Pinecone. Consistency matters. Denormalize critical filters next to the vector reference so that a single document contains both the metadata and the vector identifier. When a query arrives, run the metadata filter to narrow the candidate set, embed the text, and then run the vector search constrained to those candidates. If the metadata system is slow or temporarily overloaded, fall back to a conservative query that returns safe defaults.
Benchmarking that mirrors production reality
Design benchmarks that look like your live traffic. Define the shape of the workload with queries per second, concurrent users, vector dimension, proportion of filtered queries, and top-k. Warm the system for several minutes and discard the first minute of data. Capture the median, the ninety-fifth percentile, and the ninety-ninth percentile. Record recall at k. Track central processing unit use, memory use, garbage collection pauses, index input and output, and cache hit rates. Produce histograms in addition to averages so that tail behaviour is visible. Publish both the configuration and the raw data with the charts.
Optimization playbook for high concurrency
For HNSW, increase ef search until recall stops improving for your target percentile. Pin worker threads to the same Non-Uniform Memory Access node as their data. Reuse buffers to reduce small allocations. For IVF, size nlist near the square root of the number of vectors, and tune nprobe to meet the latency target. Use IVF with Product Quantization when memory is the constraint and prefetch the posting lists that will be probed. For the serving layer, use connection pooling and gRPC. Coalesce small queries, and when the product allows it, batch a handful of embeddings together to improve throughput without harming latency. Add a short time-to-live result cache keyed by a hash of the query text, the filters, and top-k. Warm the cache after each deploy using the top queries from the previous day.
Cost modeling that connects knobs to money
Translate configuration into spend. Memory cost grows with the number of vectors multiplied by dimension and bytes per value, divided by the compression ratio. Storage cost includes raw vectors, postings, and graph edges. Compute cost grows with queries per second multiplied by distance operations per query divided by operations per second per core. Add headroom so that the system can absorb spikes. Network cost depends on the size of the payload and the rate of queries, and it can rise sharply with cross availability zone traffic.
The expensive knobs are ef search, nprobe, the replication factor, the raw dimension size, and the level of quantization. Many teams save significant memory by moving from Float32 to Product Quantization with a small loss in recall that is acceptable once re-ranking is in place.
Reference configurations that you can start with
For ten million vectors of seven hundred and sixty eight dimensions at five hundred queries per second, a common starting point on central processing unit is IVF-PQ with nlist around four thousand and nprobe between sixteen and thirty two. When memory allows and updates are frequent, HNSW with M around thirty two and ef construction around two hundred is a solid choice, and ef search around sixty four is a useful first setting. If the corpus is small, a Flat index on graphics processing unit can provide exact recall with excellent latency.
Resilience and service level objectives
Protect the ninety-ninth percentile. Use hedged requests to replicas and return the fastest successful response. Set timeouts that are shorter than the client expectation and return partial results instead of errors. When the vector path degrades, fall back to a conservative keyword search so that the end user still receives a reasonable answer. Rebuild indexes in the background and dual-write during migrations so that you can cut over without downtime. Alert on recall dips, percentile spikes, and sudden cache miss surges, and keep a short runbook that explains the first steps to mitigate each condition.
Closing takeaway: Vector-native systems succeed when teams define the service level objective first and let that objective guide design. Use the latency budget to locate the true bottleneck. Choose an index family and tune the few parameters that matter. Place related vectors together through sharding and reduce tail latency with measured replication. Keep embeddings contiguous, warm the right caches, and combine metadata filters with nearest neighbour search. Benchmark with realistic traffic and publish the configuration with the results. Translate each dial into cost and decide where recall and spend should meet. With this discipline, you can operate a retrieval stack that meets user expectations at scale and that remains predictable to run.
Curie is our in-house platform for running vector-native retrieval in production without turning every team into index experts. It wraps the full lifecycle embedding ingest, index build/rebuild, sharding and replication, and low-latency serving behind a clean API with a small set of “real” knobs (ef_search, nprobe, quantization level, replica count) that map directly to recall, tail latency, and cost. Curie also standardizes the hot-path layout: contiguous vector storage, tiered memory (hot/warm/cold), and cache warmup on deploy, so new corpora inherit predictable performance from day one. Finally, it bakes in observability and benchmarking that mirror live traffic, letting us spot percentile regressions early and tune based on measured trade-offs rather than folklore. In short, Curie is the mechanism that turns the blueprint in this article into an operable, repeatable system at scale.
Insights That Drive Impact
Healthcare is evolving faster than ever — and those who adapt are the ones who will lead the change.
Stay ahead of the curve with our in-depth insights, expert perspectives, and a strategic lens on what’s next for the industry.


