
In the era of large language models (LLMs), the cost of intelligence has evolved beyond mere infrastructure, compute, or licensing fees. It is now transactional, dynamic, and directly linked to token flows, query patterns, and system architecture. Consequently, as engineering organizations expand their LLM-enabled applications, it becomes crucial to treat cost as a primary metric for optimization.
What Is Tokenization and Why It Matters
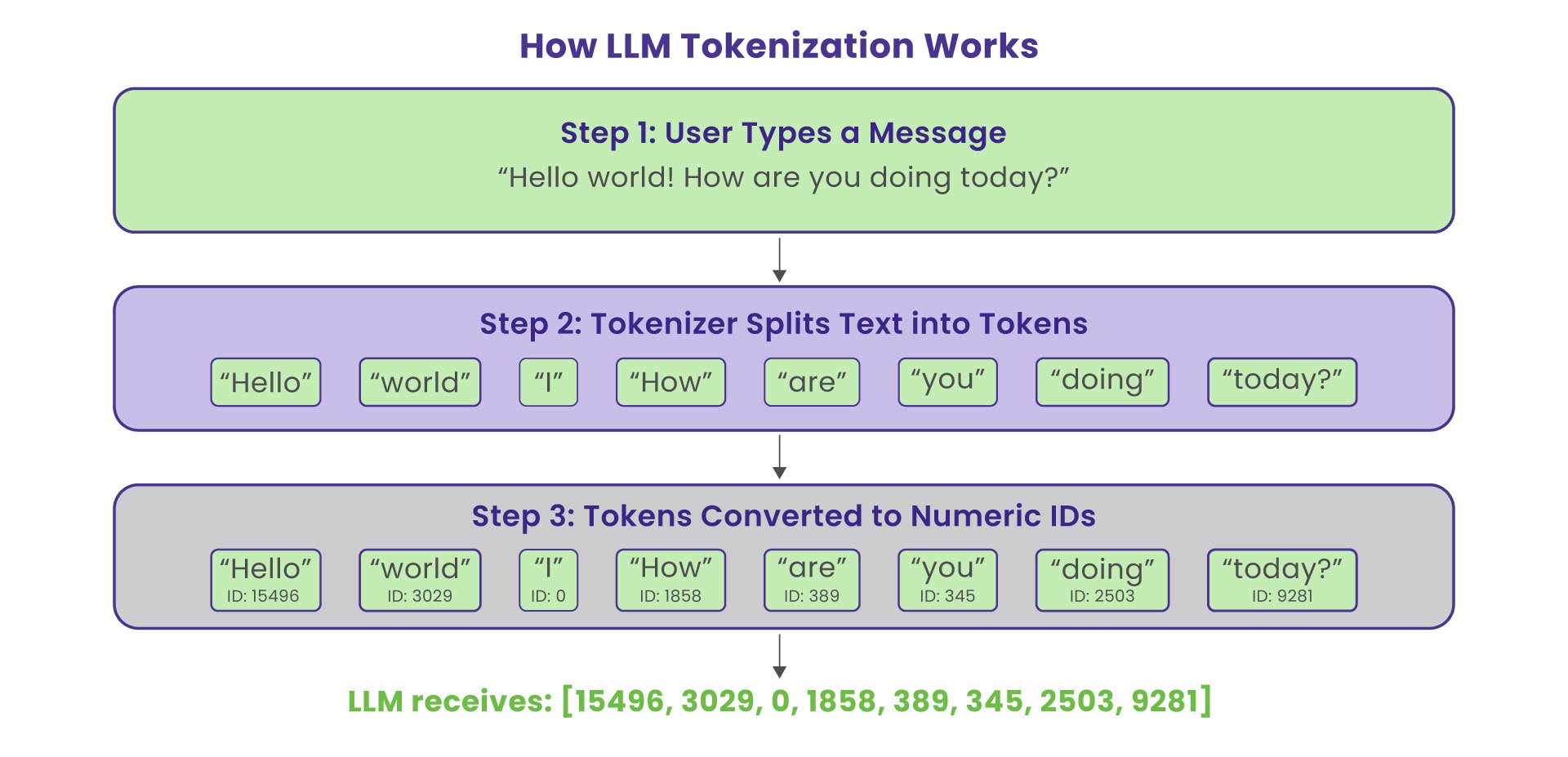
At the foundation of LLM cost lies tokenization, the process by which text is broken into smaller, model-readable units called tokens. Each token roughly represents 3–4 characters of English text.
For example:
“AI drives innovation.” → [“AI”, “ drives”, “ innovation”, “.”]
Every model request consumes input and output tokens, and each token has a price. In high-volume systems such as AI chatbots, summarization engines, or document assistants, these tokenized interactions can easily balloon into six-figure monthly expenses. This has made Token Economics a fundamental discipline for AI engineers and architects.
Why Token Economics Matter in LLM
While traditional software cost models tend to be fixed (e.g., servers, licences) or predictable (e.g., cloud instances), LLM-based services operate under usage-based billing models: input tokens, output tokens, and model tiers all contribute to cost.
For example, if your chatbot processes a million queries per month and each query consumes hundreds or thousands of tokens, the monthly bill can rapidly scale into five or six figures. Therefore, cost control in LLM applications is not just a finance concern,it is a core engineering discipline. Without built-in mechanisms to manage cost-feature rollout, experimentation, and growth becomes a budget risk.
Understanding and Optimizing the Cost Components of LLM Deployments
To optimise cost, you must first understand the cost drivers:
a) Token-based billing: The most fundamental cost component revolves around token usage. LLM providers typically charge for both input tokens (the text provided in the prompt) and output tokens (the model’s generated response). It’s crucial to note that output tokens are frequently priced higher than input tokens, making concise and efficient model outputs a key area for cost savings. This differential pricing encourages developers to design prompts that yield focused responses and to critically evaluate the necessity of verbose model outputs.
b) Inference model tier: LLM providers offer a range of models, often categorized into premium, mid-tier, and lower-tier options. Premium models, while offering superior performance and capabilities, come with a significantly higher per-token cost. Selecting an overly powerful model for a task that could be adequately handled by a less expensive alternative leads to unnecessary cost escalation. Therefore, a careful assessment of task requirements and a strategic selection of the appropriate model tier are essential for cost efficiency. This involves understanding the trade-offs between model complexity, performance, and cost.
c) Context length: Maintaining a coherent conversation with a chatbot requires carrying context forward, but it’s not necessary to include every single word. Effective context compression is crucial. Consider these key strategies:
- Summarize Regularly: Aim to summarize the conversation every 5-10 turns.
- Retain Specific Facts: Always ensure that crucial details, such as a user's order number, are preserved.
- Utilize Cost-Effective Models for Summarization: Assign summarization tasks to the most affordable models available, as this process typically does not require a complex reasoning engine.
d) Retrieval and tool/agent overhead: When implementing advanced LLM architectures such as Retrieval-Augmented Generation (RAG) pipelines, additional costs emerge. These “hidden” costs are not directly tied to LLM inference but are integral to the overall system’s operation. They include:
- Embedding indexing: The process of converting external data into numerical vector representations (embeddings) for efficient retrieval. This involves both the computational cost of generating embeddings and the storage cost for these indices.
- Retrieval operations: The actual process of querying the indexed data to find relevant information for the LLM. This can incur computational costs and, if poorly optimized, introduce latency.
- Redundant tool calls: In agent-based systems, unnecessary or inefficient calls to external tools or APIs can add to both token consumption (if the tool output is fed back to the LLM) and compute costs associated with the tool's execution. Careful design of agent logic and tool utilization is crucial.
e) Governance, routing, and quality overheads: Without robust visibility and governance mechanisms, LLM consumption can become opaque and escalate unexpectedly. This includes:
- Lack of feature/team-specific consumption tracking: If it's unclear which specific features or development teams are generating the most LLM usage, identifying and addressing cost inefficiencies becomes challenging.
- Inefficient routing: Suboptimal routing of requests to different LLM models or pipelines based on task requirements can lead to overspending. For example, routing a simple query to a premium model when a lower-tier model would suffice.
- Quality assurance iterations: Repeated iterations on prompts or model outputs during development and fine-tuning, while necessary for quality, can incur significant token costs if not managed efficiently.
Once these various cost components are thoroughly mapped and understood, organizations can then begin to engineer specific levers and strategies to reduce expenditure while diligently preserving or even enhancing the quality of their LLM-powered applications. This involves a continuous cycle of monitoring, analysis, and optimization across all stages of the LLM deployment lifecycle.

Caching, Deduplication, and Sub-Query Elimination as Cost Levers
One of the most effective engineering levers to control cost in LLM applications is avoiding unnecessary invocation of the expensive model. Three major techniques are:
a) Caching
Store responses to previously executed queries (or semantically similar ones) and reuse them instead of forwarding to the model. In practice, you may implement:
- Exact (keyword) caching: identical prompts yield identical cache keys.
- Semantic caching: use embedding-based similarity (e.g., SBERT) to detect queries that differ in wording but are semantically equivalent. Research supports that semantic caching can yield large cost savings. Important implementation tips:
- Define an appropriate similarity threshold to trade off between cache hit rate and correctness.
- Invalidate or refresh caches when data changes (e.g., underlying knowledge base updates).
- Monitor cache hit ratio and token cost savings (see next section).
b) Deduplication
Often, different parts of your system will generate repetitive or overlapping queries (e.g., two users asking the same FAQ, or internal modules generating similar sub-questions). Deduplication aims to detect and merge such queries so only one model invocation happens and the result is shared.
c) Sub-Query
Sub-query elimination goes further: if your system decomposes user requests into multiple sub-queries (e.g., agent reasoning steps, retrieval queries), you can detect when the same sub-query is reused and avoid re-running it. This reduces token usage and computation.
These techniques require instrumentation of how queries are produced, a hashing or fingerprinting scheme for sub-queries, and coordination across modules.
Cost Profiler Tied to Telemetry Events
One of the most effective engineering levers to control cost in LLM applications is avoiding unnecessary invocation of the expensive model. Three major techniques are:
a) Telemetry Instrumentation
Every LLM invocation should be traced end-to-end with metadata, including:
- Request ID and correlation ID (for linking across services)
- Tokens consumed (input/output)
- Model used (tier, provider)
- Latency and retries
- Feature/tenant/team metadata
- Cache hit or miss, deduplication status
- Retrieval steps, tool calls, sub-query count
b) Cost Profiling Metrics
From the telemetry, compute metrics such as:
- Cost per request = (input_tokens × cost_per_token_input + output_tokens × cost_per_token_output) + overhead
- Cost per feature / per team / per model
- Cache hit rate, deduplication savings, average tokens per call
- Cost per successful task (where success means correct answer/SL met) is a unit economics metric.
c) Dashboards, Alerts & Governance
Build dashboards that show real-time cost burn, as well as alerts when key metrics exceed thresholds (e.g., tokens per request spikes, cache hit rate drops below target). Governance mechanisms might include:
- Budget caps by team/feature/model
- Rate limits (requests, tokens) per user/tenant
- Model routing policies (fallbacks when the budget is exceeded)
d) Feedback Loop
Use profiler data to feed back into engineering:
- If tokens per request increase over time → revisit prompt versioning or context length
- If cache hit rate falls → tune cache keying or semantic similarity thresholds
- If a feature shows high cost per success → triage whether it needs premium model or can degrade gracefully
By aligning telemetry with cost, you convert token economics from opaque bills into actionable engineering metrics.
Conclusion: From Token Bills to Responsible AI Economics
Scaling intelligent applications via LLMs without cost discipline is a recipe for runaway budgets. But engineering cost control is entirely feasible when you treat token economics as a first-class engineering concern.
Key takeaways:
- Make cost visible: instrument tokens, latency, model usage, cache hits.
- Avoid unnecessary spending: caching, deduplication, and sub-query elimination reduce model calls and token consumption.
- Route intelligently: cheaper models for simpler tasks, premium only when needed.
- Govern proactively: model access, budgets, quotas, and quality-cost trade-offs need to be embedded in your architecture.
- Close the loop: feed profiler data into continuous optimisation, iterate on prompts, tiering, and routing.
By adopting these practices, you turn what may seem like an uncontrollable “token bill” into a predictable engineering metric- and thereby you enable responsible, scalable, cost-efficient AI. Agentic AI platforms like Curie make these principles actionable at scale. By centralizing retrieval, context management, and cost-aware routing, Curie reduces unnecessary token usage before requests reach expensive models. Coupled with built-in observability and performance metrics, it turns token economics from an abstract concern into a measurable, governable signal, enabling teams to scale LLM applications responsibly, efficiently, and predictably.



